Transcribing
Transcription Workflow:
- Segment Images - Mark text lines/fragments, group into columns/sections, assign to layers
- Set Text Flow - Order sections, lines, and pages for continuous reading
- Type Transcriptions - Enter text for each fragment line-by-line
Three Interfaces Available: Classic (TPEN 2.8-style), Modern (streamlined), Complex (glosses/challenging layouts)
Extensible: Public API allows custom transcription interfaces for specialized needs or crowd-sourcing
Reading the Page
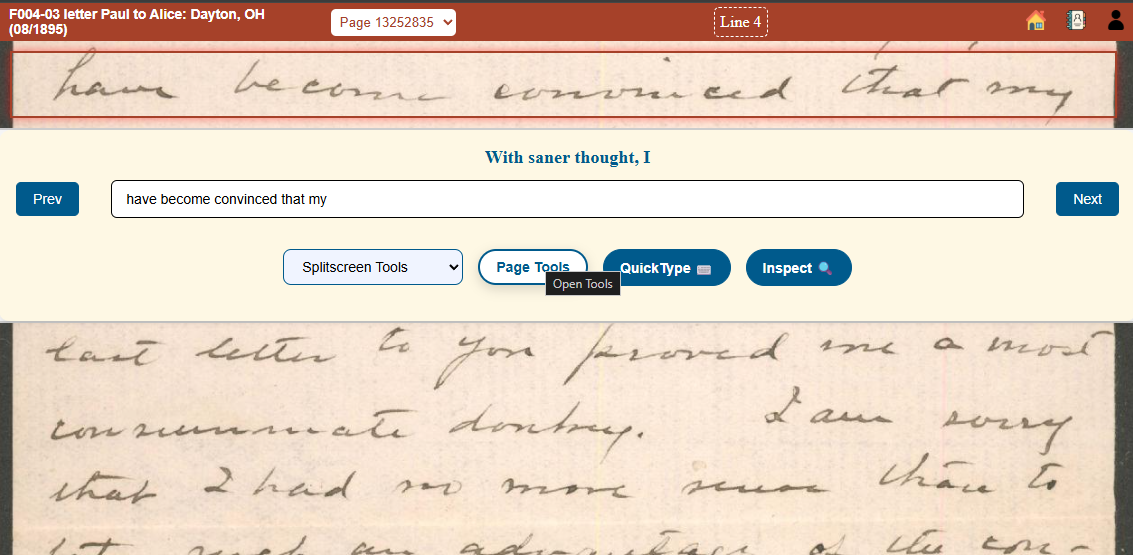
A typical transcription project will have an image with a number of lines to be transcribed. The lines can be grouped together into columns or sections. The order of the sections and the lines within them indicate the line-by-line flow of text. In multipage projects, the pages are also aligned for continuous text. Transcriptions may also be layered such as in a glossed text with commentary, for example. In this case, the groups of lines will be organized in parallel layers that do not have to share the same order.
Segmenting the Images
While imported TPEN 2.8 projects and some IIIF resources may have fragment selections indicating the lines of text, most images will be unadorned in a new Project. Depending on the interface used, annotations marking the text fragments and ordering them may be generated and presented for correction or manually assigned on a blank page. For each page, the text flow may be divided into groups, assigned to a layer, and then linked to its adjacent pages. Most interfaces will assign a reasonable default for the types of materials expected, saving the paleographer effort. For example, a medieval Latin text would assume front-to-back, top-to-bottom, left-to-right reading in a one or two column layout. Once a page’s image is correctly bounded, a user may move logically through the fragments (line-by-line) and type in the text transcription.
Transcription Interfaces
TPEN will launch with three different interfaces for transcription. The first will largely resemble the TPEN 2.8 interface, with the addition of new grouping and ordering features. The second will be a more modern interface, with a more streamlined layout and a more minimalist approach to annotation. The third will focus on texts with challenging layouts and text flow, such as bracketed texts with interlinear glosses and intervening illustrations or figures.
One exciting feature of TPEN3, however, is that the authorization and annotation systems are completely available with a public API. Third-parties or individual researchers can build their own transcription interfaces. A specific collection might need a focused tool or interaction for the unique format of its documents or sets of crowd-sourced or machine-generated annotations may benefit from a clean interface for proof-reading.